 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
Dec 20, 2025Real-world software engineering tasks require coding agents that can operate over massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK integrates a unified orchestrator with hierarchical working memory for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In addition, we introduce a meta-agent that automates the synthesis, evaluation, and refinement of agent configurations through a build-test-improve loop, enabling rapid adaptation to new tasks, environments, and tool stacks. Instantiated with these mechanisms, CCA demonstrates strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA reaches a Resolve@1 of 54.3%, exceeding prior research baselines and comparing favorably to commercial results, under identical repositories, model backends, and tool access.
Phantora: Live GPU Cluster Simulation for Machine Learning System Performance Estimation
May 02, 2025To accommodate ever-increasing model complexity, modern machine learning (ML) systems have to scale to large GPU clusters. Changes in ML model architecture, ML system implementation, and cluster configuration can significantly affect overall ML system performance. However, quantifying the performance impact before deployment is challenging. Existing performance estimation methods use performance modeling or static workload simulation. These techniques are not general: they requires significant human effort and computation capacity to generate training data or a workload. It is also difficult to adapt ML systems to use these techniques. This paper introduces, Phantora, a live GPU cluster simulator for performance estimation. Phantora runs minimally modified ML models and frameworks, intercepting and simulating GPU-related operations to enable high-fidelity performance estimation. Phantora overcomes several research challenges in integrating an event-driven network simulator with live system execution, and introduces a set of techniques to improve simulation speed, scalability, and accuracy. Our evaluation results show that Phantora can deliver similar estimation accuracy to the state-of-the-art workload simulation approach with only one GPU, while reducing human effort and increasing generalizability.
Semantic Ads Retrieval at Walmart eCommerce with Language Models Progressively Trained on Multiple Knowledge Domains
Feb 13, 2025



Sponsored search in e-commerce poses several unique and complex challenges. These challenges stem from factors such as the asymmetric language structure between search queries and product names, the inherent ambiguity in user search intent, and the vast volume of sparse and imbalanced search corpus data. The role of the retrieval component within a sponsored search system is pivotal, serving as the initial step that directly affects the subsequent ranking and bidding systems. In this paper, we present an end-to-end solution tailored to optimize the ads retrieval system on Walmart.com. Our approach is to pretrain the BERT-like classification model with product category information, enhancing the model's understanding of Walmart product semantics. Second, we design a two-tower Siamese Network structure for embedding structures to augment training efficiency. Third, we introduce a Human-in-the-loop Progressive Fusion Training method to ensure robust model performance. Our results demonstrate the effectiveness of this pipeline. It enhances the search relevance metric by up to 16% compared to a baseline DSSM-based model. Moreover, our large-scale online A/B testing demonstrates that our approach surpasses the ad revenue of the existing production model.
LayerDAG: A Layerwise Autoregressive Diffusion Model for Directed Acyclic Graph Generation
Nov 04, 2024



Directed acyclic graphs (DAGs) serve as crucial data representations in domains such as hardware synthesis and compiler/program optimization for computing systems. DAG generative models facilitate the creation of synthetic DAGs, which can be used for benchmarking computing systems while preserving intellectual property. However, generating realistic DAGs is challenging due to their inherent directional and logical dependencies. This paper introduces LayerDAG, an autoregressive diffusion model, to address these challenges. LayerDAG decouples the strong node dependencies into manageable units that can be processed sequentially. By interpreting the partial order of nodes as a sequence of bipartite graphs, LayerDAG leverages autoregressive generation to model directional dependencies and employs diffusion models to capture logical dependencies within each bipartite graph. Comparative analyses demonstrate that LayerDAG outperforms existing DAG generative models in both expressiveness and generalization, particularly for generating large-scale DAGs with up to 400 nodes-a critical scenario for system benchmarking. Extensive experiments on both synthetic and real-world flow graphs from various computing platforms show that LayerDAG generates valid DAGs with superior statistical properties and benchmarking performance. The synthetic DAGs generated by LayerDAG enhance the training of ML-based surrogate models, resulting in improved accuracy in predicting performance metrics of real-world DAGs across diverse computing platforms.
Enhanced E-Commerce Attribute Extraction: Innovating with Decorative Relation Correction and LLAMA 2.0-Based Annotation
Dec 09, 2023



The rapid proliferation of e-commerce platforms accentuates the need for advanced search and retrieval systems to foster a superior user experience. Central to this endeavor is the precise extraction of product attributes from customer queries, enabling refined search, comparison, and other crucial e-commerce functionalities. Unlike traditional Named Entity Recognition (NER) tasks, e-commerce queries present a unique challenge owing to the intrinsic decorative relationship between product types and attributes. In this study, we propose a pioneering framework that integrates BERT for classification, a Conditional Random Fields (CRFs) layer for attribute value extraction, and Large Language Models (LLMs) for data annotation, significantly advancing attribute recognition from customer inquiries. Our approach capitalizes on the robust representation learning of BERT, synergized with the sequence decoding prowess of CRFs, to adeptly identify and extract attribute values. We introduce a novel decorative relation correction mechanism to further refine the extraction process based on the nuanced relationships between product types and attributes inherent in e-commerce data. Employing LLMs, we annotate additional data to expand the model's grasp and coverage of diverse attributes. Our methodology is rigorously validated on various datasets, including Walmart, BestBuy's e-commerce NER dataset, and the CoNLL dataset, demonstrating substantial improvements in attribute recognition performance. Particularly, the model showcased promising results during a two-month deployment in Walmart's Sponsor Product Search, underscoring its practical utility and effectiveness.
Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
May 26, 2023



Benchmarking and co-design are essential for driving optimizations and innovation around ML models, ML software, and next-generation hardware. Full workload benchmarks, e.g. MLPerf, play an essential role in enabling fair comparison across different software and hardware stacks especially once systems are fully designed and deployed. However, the pace of AI innovation demands a more agile methodology to benchmark creation and usage by simulators and emulators for future system co-design. We propose Chakra, an open graph schema for standardizing workload specification capturing key operations and dependencies, also known as Execution Trace (ET). In addition, we propose a complementary set of tools/capabilities to enable collection, generation, and adoption of Chakra ETs by a wide range of simulators, emulators, and benchmarks. For instance, we use generative AI models to learn latent statistical properties across thousands of Chakra ETs and use these models to synthesize Chakra ETs. These synthetic ETs can obfuscate key proprietary information and also target future what-if scenarios. As an example, we demonstrate an end-to-end proof-of-concept that converts PyTorch ETs to Chakra ETs and uses this to drive an open-source training system simulator (ASTRA-sim). Our end-goal is to build a vibrant industry-wide ecosystem of agile benchmarks and tools to drive future AI system co-design.
A Deep Value-network Based Approach for Multi-Driver Order Dispatching
Jun 08, 2021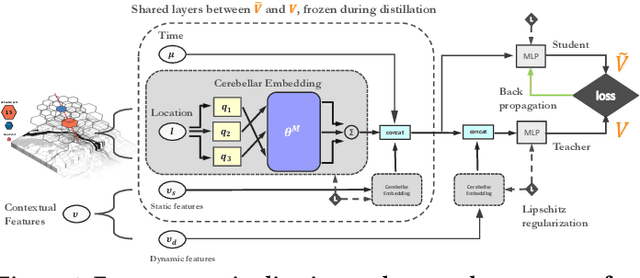
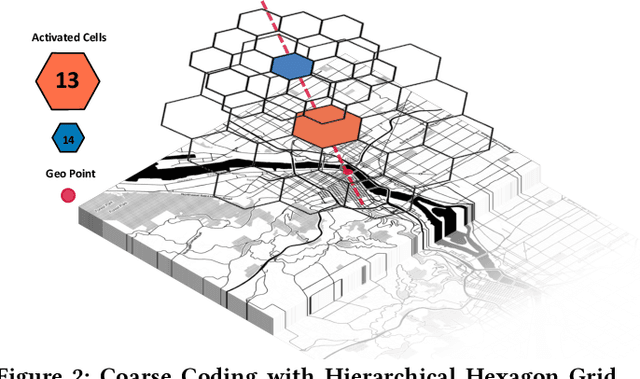
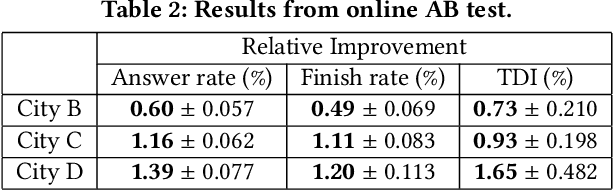
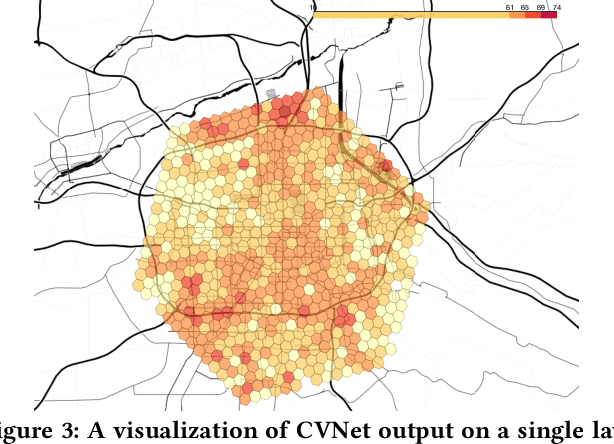
Recent works on ride-sharing order dispatching have highlighted the importance of taking into account both the spatial and temporal dynamics in the dispatching process for improving the transportation system efficiency. At the same time, deep reinforcement learning has advanced to the point where it achieves superhuman performance in a number of fields. In this work, we propose a deep reinforcement learning based solution for order dispatching and we conduct large scale online A/B tests on DiDi's ride-dispatching platform to show that the proposed method achieves significant improvement on both total driver income and user experience related metrics. In particular, we model the ride dispatching problem as a Semi Markov Decision Process to account for the temporal aspect of the dispatching actions. To improve the stability of the value iteration with nonlinear function approximators like neural networks, we propose Cerebellar Value Networks (CVNet) with a novel distributed state representation layer. We further derive a regularized policy evaluation scheme for CVNet that penalizes large Lipschitz constant of the value network for additional robustness against adversarial perturbation and noises. Finally, we adapt various transfer learning methods to CVNet for increased learning adaptability and efficiency across multiple cities. We conduct extensive offline simulations based on real dispatching data as well as online AB tests through the DiDi's platform. Results show that CVNet consistently outperforms other recently proposed dispatching methods. We finally show that the performance can be further improved through the efficient use of transfer learning.
Efficient Deep Reinforcement Learning through Policy Transfer
Feb 19, 2020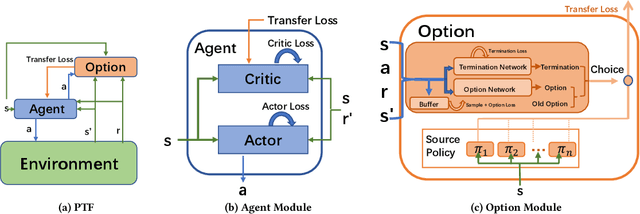
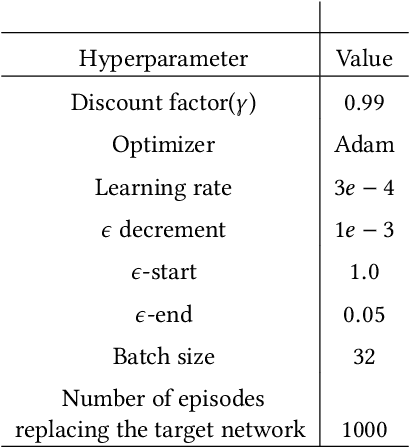
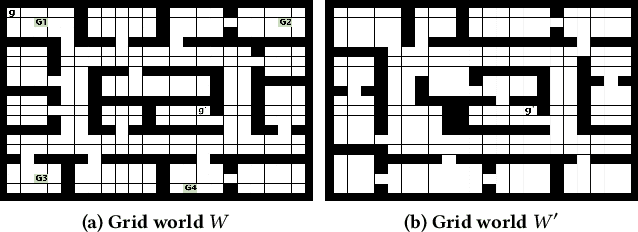
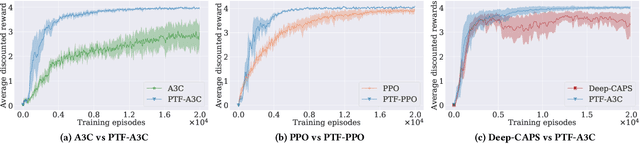
Transfer Learning (TL) has shown great potential to accelerate Reinforcement Learning (RL) by leveraging prior knowledge from past learned policies of relevant tasks. Existing transfer approaches either explicitly computes the similarity between tasks or select appropriate source policies to provide guided explorations for the target task. However, how to directly optimize the target policy by alternatively utilizing knowledge from appropriate source policies without explicitly measuring the similarity is currently missing. In this paper, we propose a novel Policy Transfer Framework (PTF) to accelerate RL by taking advantage of this idea. Our framework learns when and which source policy is the best to reuse for the target policy and when to terminate it by modeling multi-policy transfer as the option learning problem. PTF can be easily combined with existing deep RL approaches. Experimental results show it significantly accelerates the learning process and surpasses state-of-the-art policy transfer methods in terms of learning efficiency and final performance in both discrete and continuous action spaces.
Interactive Reinforcement Learning with Dynamic Reuse of Prior Knowledge from Human/Agent's Demonstration
May 11, 2018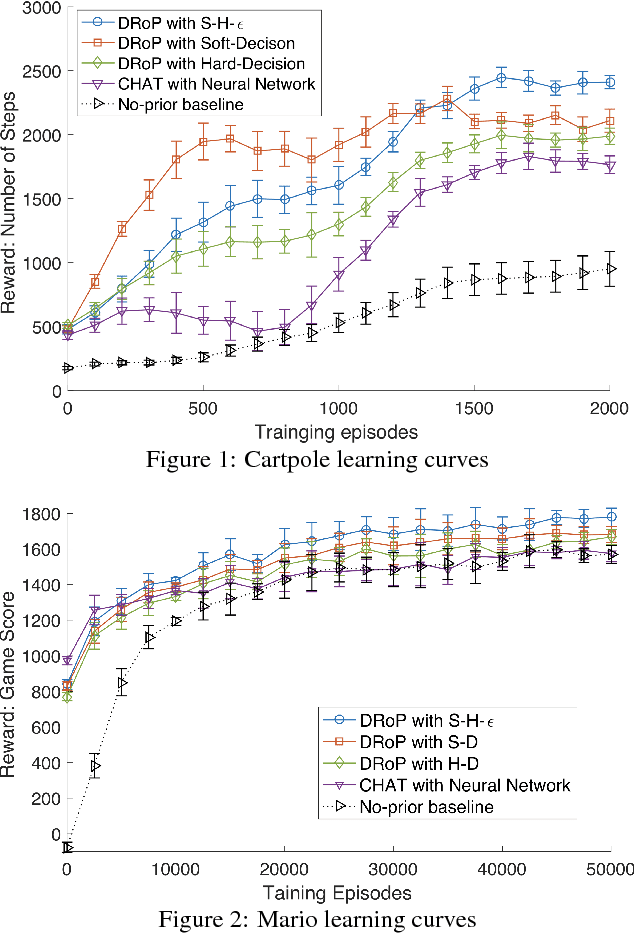
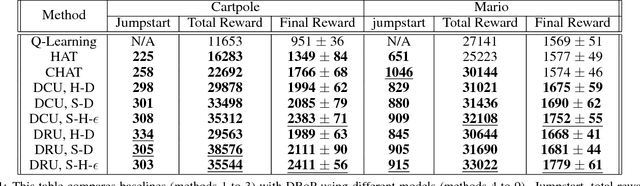
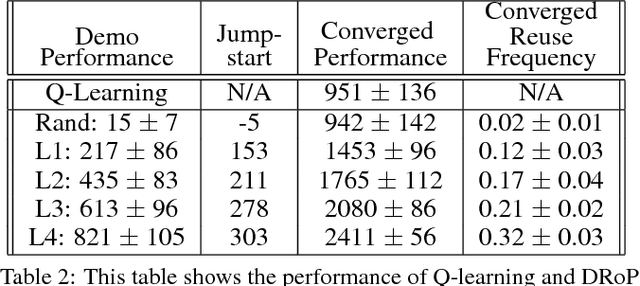
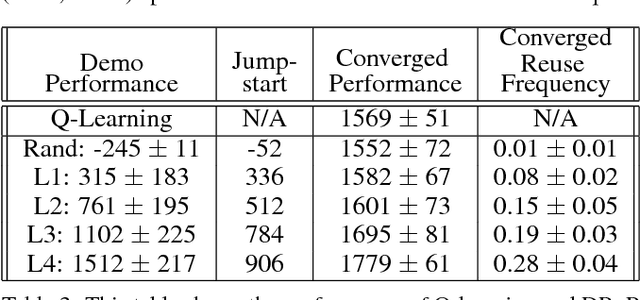
Reinforcement learning has enjoyed multiple successes in recent years. However, these successes typically require very large amounts of data before an agent achieves acceptable performance. This paper introduces a novel way of combating such requirements by leveraging existing (human or agent) knowledge. In particular, this paper uses demonstrations from agents and humans, allowing an untrained agent to quickly achieve high performance. We empirically compare with, and highlight the weakness of, HAT and CHAT, methods of transferring knowledge from a source agent/human to a target agent. This paper introduces an effective transfer approach, DRoP, combining the offline knowledge (demonstrations recorded before learning) with online confidence-based performance analysis. DRoP dynamically involves the demonstrator's knowledge, integrating it into the reinforcement learning agent's online learning loop to achieve efficient and robust learning.